




Datová věda je v současnosti jedním z nejoblíbenějších oborů v oblasti informatiky. Možná o tom ani nevíte, ale setkáváte se s ní každý den. Třeba když vám YouTube doporučí video nebo když Facebook rozpozná obličeje spolužáků. Modely vytvořené datovou vědou jsou také mozkem samořídících automobilů, inteligentních robotů, programů pro odhalování nových počítačových virů nebo vzorců pro předpověď počasí.
Nepřeberné množství dat
V posledních letech, kdy naši přítomnost ovládly počítače, chytrá zařízení a neustálé připojení na internet, máme najednou k dispozici obrovské množství tzv. nestrukturovaných dat. Mezi ně patří například různé příspěvky, fotky nebo videa na sociálních sítích. Spoustu dat také produkujeme, aniž bychom o tom věděli. Jde třeba o informace o poloze z GPS, čas pořízení fotky na mobil nebo délka naší návštěvy webové stránky. Aby z nich mohli programátoři vytvořit něco užitečného, musí je nejprve rozebrat a roztřídit.

Jak je zpracovat?
Každá analýza začíná otázkou, co vlastně chceme z dat zjistit. Už jsme si řekli, že třeba YouTube vám s jejich pomocí doporučí písničky. My se pro příklad rozhodneme provést analýzu komentářů na facebookovém profilu ábíčka, která nám umožní automaticky rozpoznat, jestli nám přišel pochvalný, nebo kritický příspěvek. Nejprve si zkopírujeme posledních několik komentářů k našim postům. Pak si v nich najdeme klíčová slova, která budou sloužit jako základ pro rozlišení pozitivního a negativního komentáře. Taky využijeme emoji, protože druh smajlíka, který naši čtenáři v postech použijí, rovněž vypovídá o tom, co si o nás myslí.

Jak vychovat stroj
Datoví vědci pro modelování dat často používají strojové učení. Díky němu zvládne program automaticky doporučit třeba stránky, které by se vám mohly líbit, věci, které byste si mohli koupit nebo v našem případě odlišit pozitivní a negativní komentář. Program pro strojové učení si rozdělíme do dvou podsouborů. V tom prvním, tréninkovém, ho budeme učit rozlišovat pozitivní a negativní posty. V tom druhém pak vyzkoušíme, zda stroj dovede podle toho, co se naučil během tréninku, správně detekovat nový příspěvek. Když pak někdo napíše nový komentář na naši facebookovou stránku, dokáže ho program správně zařadit.
Analýza sociálních sítí:

Zkuste to sami!
Analýzu dat může provádět programátor i laik. Pokud neumíte programovat, můžete sáhnout po předpřipravené aplikaci, která vám ušetří spoustu práce se strojovým učením. Bohužel ale musíte počítat s tím, že univerzální program umí analyzovat jen běžně hledané parametry. Pokud chcete v datech nalézt něco výjimečného, musíte si sami nástroj pro analýzu dat naprogramovat sami. Nejpopulárnější jazyk datových horníků se jmenuje Python. Pokud si chcete analýzu dat jen tak vyzkoušet, zkuste třeba NodeXL, který je velmi přístupný a jednoduchý na ovládání.

Pozor na osobní info!
Sbírat a zpracovávat data o cizích lidech ale není být jen tak. Před každou analýzou je potřeba prostudovat smluvní podmínky sociální sítě a také právní podmínky země, kde se nacházíme. Analýza dat také probouzí některé morální otázky. Ačkoli uživatelé zaškrtnutím políčka souhlasili se zpracováním jejich osobních dat, je pravděpodobné, že většina z nich o tom vůbec neví. Slušní datoví analytici proto maximálně respektují soukromí uživatelů a snaží se získaná data anonymizovat, aby nikdo nemohl poznat, odkud přesně pocházejí.
Co o nás prozradí post?
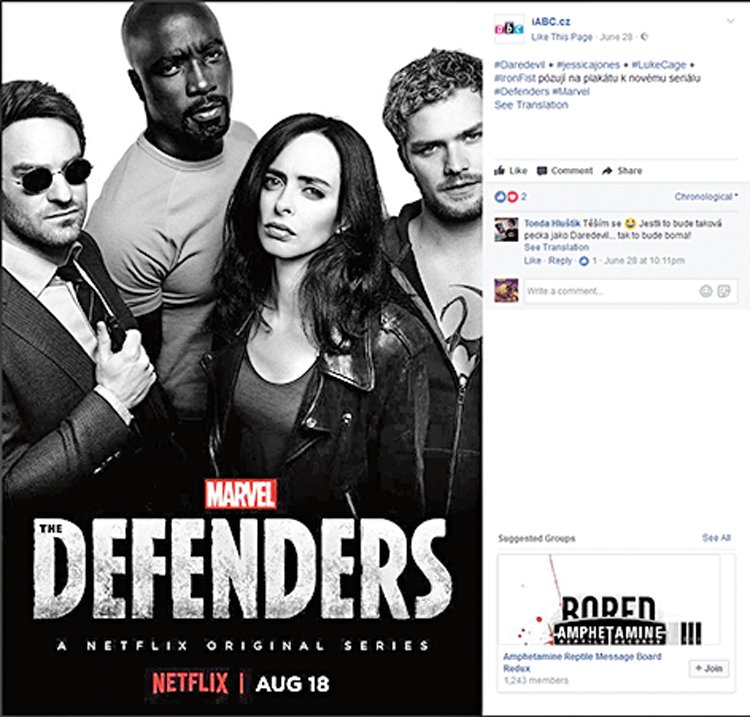
1 Jméno a příjmení slouží společně s datem narození jako základ pro shromáždění dat o uživateli sociální sítě
2 Čas a místo zveřejnění prozrazuje, kde přesně se v určitou chvíli uživatel nachází
3 Počet lajků, komentářů a sdílení se používají k zjištění, jak moc je téma, kterému se post věnuje, populární
4 Text a fotografie postu jsou nestrukturovaná data, která je potřeba zpracovat pro analýzu
5 Text komentářů a jména komentujících jsou rovněž nestrukturovaná data ke zpracovaní


















